
파이토치(PyTorch)
-딥러닝 프레임워크: 딥러닝 응용 프로그램 개발을 위해 여러 라이브러리나 모듈을 효율적으로 사용할 수 있도록 하나로
묶어 놓은 것이다.
-페이스북에서 개발된 프레임워크
-토치(torch)라는 머신 러닝 라이브러리에 바탕을 두고 만들어졌다.
-학습속도가 텐서플로우보다 빠르다.
-파이토치는 메모리 연산과 동시에 신경망 사이즈를 최적으로 바꾸면서 동작할 수 있다.
파이토치 설치 링크
https://pytorch.org/get-started/locally/
CPU와 GPU
CPU는 GPU에 비해 고차원의 일을 수행할 수 있다. 대신 많은 수의 파라미터 값을 계산하기에는 속도가 느리다.
GPU는 파라미터 값을 병렬적으로 빠르게 계산할 수 있다.
CUDA역할
-파이썬에서 GPU를 인식하고 딥러닝 프레임워크에서 사용하기 위함
-GPU에서 병렬 처리를 수행하는 알고리즘을 각종 프로그래밍 언어에 사용할 수 있도록 해주는
GPGPU(General-Purpose comuting on Graphics Processing Units)기술
다운로드 링크
https://developer.nvidia.com/cuda-toolkit
CuDNN(nvidia CUDA Deep Neral Network Library)
-GPU가속화 라이브러리의 기초 요소와 같은 일반적인루틴을 빠르게 이행할 수 있도록 해주는 라이브러리
-반드시 CUDA와 함께 설치해야한다.
다운로드 링크
https://developer.nvidia.com/cudnn
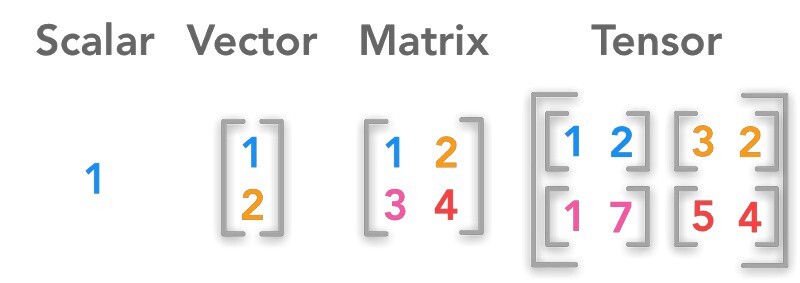
데이터를 표현하는 단위
스칼라(Scalar)
-상숫값
-하나의 값을 표현할 때 1개의 수치로 표현한것
벡터(Vector)
-하나의 값을 표현할 때 2개 이상의 수치로 표현한 것
행렬(Matrix)
-2개 이상의 벡터 값을 통합해 구성된 값
-선형 대수의 기본 단위
텐서(Tensor)
-행렬은 2차원의 배열로 표현할 수 있고 텐서는 2차원 이상의 배열로 표현할 수 있다.

Autograd
-파이토치를 이용해 코드를 작성할 때 Back Propagation을 이용해 파라미터를 업데이트 하는 방법은 Autograd 방식으로 쉽게 구현할 수 있도록 설정돼 있다.
-오차 역전파(Back Propagation): 컴퓨터는 주어진 입력값을 신경망을 거쳐 출력값으로 반환한다. 신경망은 <입력 - 신경망 - 출력>과 같이 좌측에서 우측으로의 진행방향을 갖는다. 그러나 훈련을 위해서 오차 역전파(Back-propagation) 과정에서는 이와는 반대의 진행방향을 갖는다. 오차 역전파 과정은 컴퓨터가 예측값의 정확도를 높이기 위해 출력값과 실제 예측하고자 하는 값을 비교하여 가중치를 변경하는 작업을 말한다.
간단 딥러닝 모델 설계
-방정식 내에 존재하는 파라미터를 어떻게 업데이트할 수 있는지 보기위함
전체 코드
import torch
if torch.cuda.is_available():#현재 파이썬이 실행되고 있는 환경에서 torch module을 이용할 때 GPU를 이용해 계산할 수 있는지 파악하는 메서드
DEVICE=torch.device('cuda')
else:
DEVICE=torch.device('cpu')
print(DEVICE)
#-----------------------------------------------------------------------------------------
BATCH_SIZE=64#딥러닝 모델에서 파라미터를 업데이트할 때 계산되는 데이터의 개수
INPUT_SIZE=1000#딥러닝 모델에서 Input의 크기이자 입력층의 노드 수를 의미(현재 입력 데이터의 크기가 1000 즉, 1000크기의 벡터 값을 의미)
HIDDEN_SIZE=100#딥러닝 모델에서 Input을 다수의 파라미터를 이용해 계산한 결과에 한 번 더 계산되는 파라미터 수를 의미(입력층에서 은닉층으로 전달됐을 때 은닉층의 노드 수를 의미)
OUTPUT_SIZE=10# 딥러닝 모델에서 최종으로 출력되는 값으 벡터의 크기를 의미한다.(치종으로 비교하고자 하는 레이블의 크기와 동일하게 설정한다.)
#1000크기의 벡터값을 64개 이용한다(64,1000)
#(64, 1000)의 Input들이 (1000,100)크기의 행렬과 핼렬 곱을 계산하기 위해 설정한 수
#-----------------------------------------------------------------------------------------
x=torch.randn(BATCH_SIZE,
INPUT_SIZE,
device=DEVICE,
dtype=torch.float,
requires_grad=False)
#Input
#x는 (64,1000)모양의 데이터가 생성된다.
#해당 데이터는 Input으로 이용되어 Gradient를 계산할 필요가 없다.(따라서 requires_grad=False)
y=torch.randn(BATCH_SIZE,
OUTPUT_SIZE,
device=DEVICE,
dtype=torch.float,
requires_grad=False)
#Output
#Input의 설정과 동일
#BATCH_SIZE만큼 결괏값이 필요하다.
# Output과의 오차를 계산하기 위해 Output의 크기를 10으로 설정
w1=torch.randn(INPUT_SIZE,
HIDDEN_SIZE,
device=DEVICE,
dtype=torch.float,
requires_grad=True)
#업데이트할 파라미터 값
#Input의 데이터 크기가 1000이며 이와 행렬 곱을 하기위해 다음 행의 값이 1000이어야한다.
#행렬곱을 이용해 100크기의 데이터를 생성하기위해 (1000,100)크기의 데이터를 생성한다
#requires_grad=True을 이용해 Gradient를 계산할 수 있도록 설정한다.
w2=torch.randn(HIDDEN_SIZE,
OUTPUT_SIZE,
device=DEVICE,
dtype=torch.float,
requires_grad=True)
#w1과 x를 행렬 곱한 결과에 계산할수 있는 데이터여야 한다.
#w1과 x를 곱한 결과는 (64,100)이며 이를 계산하기위해 (100,10)모양을 만든다
#(100,10)은 Output이 계살될 수 있도록 출력 크기를 맞춘것
#w2도 Back Propagation을 통해 업데이트해야 하는 대상이므로 requires_grad=True을 이용해 Gradient를 계산할 수 있도록 설정한다.
#randn은 평균이 0, 표준편차가 1인 정규붙포에서 샘플링한 값(데이터를 만든다는 것을 의미)
#-----------------------------------------------------------------------------------------
learning_rate=1e-6
#파라미터를 업데이트할 때 Gradient를 계산한 결괏값에 1보다 작은 값을 곱해 업데이트 한다. 이를 Learning Rate라고 한다.
#learning_rate를 어떻게 설정하느냐에 따라 Gradient에 따른 학습 정도가 결정된다.
#디러닝 모델에서 파라미터 값을 업데이트할 때 가장 중요한 하이퍼 파라미터이다.
for t in range(1,501):
y_pred=x.mm(w1).clamp(min=0).mm(w2)
#x.mm(w1)는 Input x와 w1간의 행렬 곱을 이용해 나온 결괏값을 계산
#clamp는 비선형 함수를 적용하는 함수(ReLU()와 같은 역할을 한다.) 최솟값은0이고 0보다 큰 값은 자기 자식을 갖는다.
#이를 이용해 높은 표현력을 가지는 방정식을 얻게 된다.
#.mm(w2)앞에서 계산된 결과와 w2의 행렬 곱을 한 번 더 계산한다.
#행렬 곱을 한 결과는 딥러닝 모델에서의 Output을 의미하며 이는 예측갑이라고 표현된다.
loss=(y_pred-y).pow(2).sum()
#예측값과 실제 레이블 값을 비교해 오차를 계산한 값 loss
#예측값과 실제 값의 차이를 계산 후 pow(2)를 이용해 제곱한다.
#이 제곱한 값을 sum()함수로 합을 계산한다.
if t % 100 ==0:#100번째 반복마다 loss값 모니터링
print("Iteration: ",t, "\t","Loss: ",loss.item())
loss.backward()
#계산된 Loss값에 대해 각 파라미터 값에 대해 Gradient를 계산한고 이를 통해 Back Propagtion을 진행한다는 것을 의미한다.
with torch.no_grad():
#각 파라미터 값에 대해 Gradient를 계산한 결과를 이용해 파라미터 값을 업데이트할 때는 해당 시점의 Gradient값을 고정한 후 업데이트를 진행한다,
#코드가 실행되는 시점에서 Gradient값을 고정한다는 의미
w1 -=learning_rate*w1.grad
w2 -=learning_rate*w2.grad
#Gradient값을 고정한 상태에서 w1, w2의 Gradient값과 learning_rate값을 곱한 결괏값을 기존 w1,w2에서 빼준다.
#음수를 이용한 이유는 Loss값이 최소로 계산될 수 있는 파라미터 값을 찾기 위해 Gradient값에 대한 반대 방향으로 계산한다는 것을 의미한다.
w1.grad.zero_()
w2.grad.zero_()
#파라미터 값을 업데이트 했다면 각 파라미터 값의 Gradient를 초기화해 다음 반복문을 진행할 수 있도록 Gradient값을 0으로 설정한것이다.
#다음 Back propagtion을 진행할 때 gradient값을 새로 계산하기 때문이다.
결과

Loss값이 줄어드는 것을 확인할 수 있고 Loss값이 줄어든다는 것을 Input이 w1과 w2를 통해 계산된 결괏값과 y값이 점점 비슷해진다는 것을 의미하며 y값과 비슷한 Output을 계산할 수 있도록 w1과 w2가 계산된다는 것을 알 수 있다.
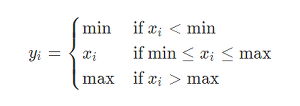
실행환경: Anaconda jupyter
참고 및 사진출처
'코딩 > 메모' 카테고리의 다른 글
| 클라우드 컴퓨팅 서비스(SaaS, IaaS, PaaS) (0) | 2022.12.23 |
|---|---|
| (딥 러닝) Yolov5 Custom Training (0) | 2022.11.27 |
| (딥 러닝)yolov5모델 실행시키기 (0) | 2022.11.27 |



댓글